
研究证实新专利分析模型性能强劲
美国国家经济研究局(NBER)发布的一项研究证实了马克斯·普朗克创新与竞争研究所研究团队开发的专利分析模型 PaECTER 的出色表现。该模型在专利审查和创新研究的关键任务中与其他模型相比名列前茅。
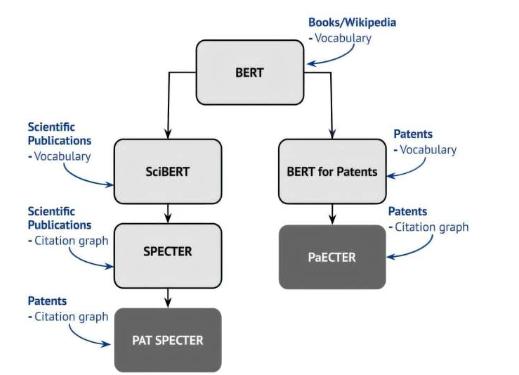
PaECTER (使用引文信息变换器的专利级表示学习)由 Mainak Ghosh、Sebastian Erhardt、Michael E. Rose、Erik Buunk 和 Dietmar Harhoff 开发,它采用了先进的基于变换器的机器学习技术,并根据专利引文数据进行了微调。
该模型专门用于解决专利文本分析的复杂挑战,并在相似专利的识别和分类方面提供了显著的改进,对于专利审查员和创新研究人员都具有很高的价值。
NBER 的新工作论文“专利文本和长期创新动力:模型选择的关键作用”严格将 PaECTER 与其他自然语言处理 (NLP) 模型进行了比较。
作者 Ina Ganguli(马萨诸塞大学阿默斯特分校)、Jeffrey Lin(费城联邦储备银行)、Vitaly Meursault(费城联邦储备银行)和 Nicholas Reynolds(埃塞克斯大学)评估了模型在专利干扰任务中的表现,其中多位发明人声称拥有类似的发明。
研究得出的结论是,与 TF-IDF(词频 - 逆文档频率)等传统模型相比,PaECTER 显著降低了误报率并提高了效率。该研究还强调了 PaECTER 与其他现代模型(如 GTE 和 S-BERT(广义文本嵌入和句子 BERT))相比的能力,这些模型以数字向量的形式表示文本,以捕获有关单词或整个句子的语义信息。
PaECTER不仅在干扰识别等专家驱动的任务中表现出色,而且在更广泛的专利分类任务中也表现出色,进一步增强了其多功能性。
PaECTER 的开发人员之一 Mainak Ghosh 表示: “我们很高兴 PaECTER 的性能得到了 NBER 研究的验证,这表明了它在专利相似性分析方面的优势,并证实了它作为创新和知识产权领域工作者的可靠工具的作用。”“这次独立验证进一步加强了它在专利审查领域的相关性。”
PaECTER模型可在 Hugging Face 平台上使用,可供全球研究人员、政策制定者和专利专业人士使用。NBER 研究表明,该模型性能强劲,凸显了其在改进专利数据处理方式方面的价值,有助于随着时间的推移更准确、更有效地分析专利创新。截至今日,PaECTER 的下载量已超过 140 万次。